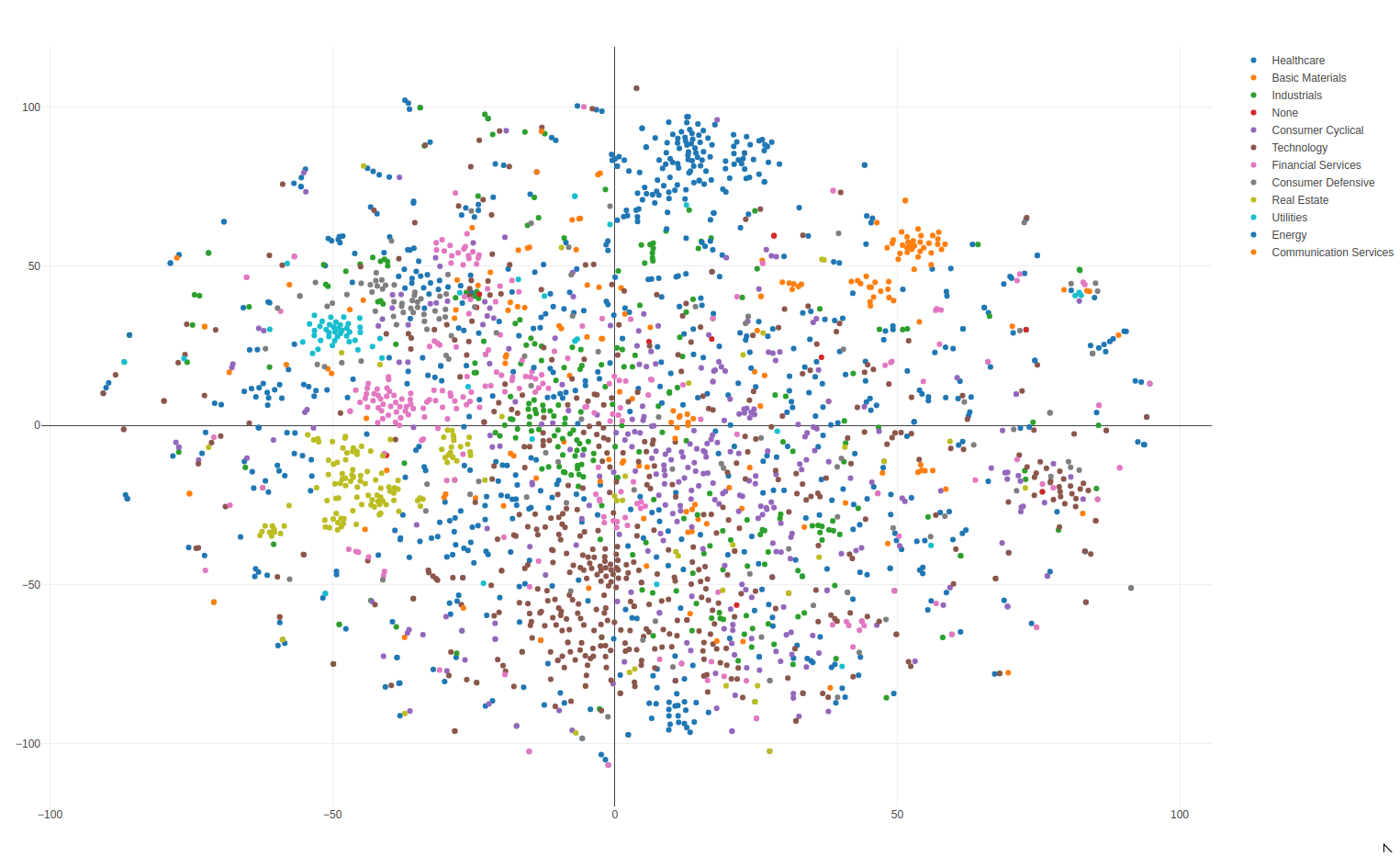
 [OC] Dimensionality reduction of stock trading patterns
[OC] Dimensionality reduction of stock trading patternsSubmitted by PsychologicalEgg9377 t3_11o7mmt in dataisbeautiful
PsychologicalEgg9377 OP t1_jbrqmco wrote
I assumed most people on this sub would be familiar with nonlinear dimensionality reduction but it looks some are not.
https://en.wikipedia.org/wiki/Nonlinear_dimensionality_reduction
This family of algorithms takes a data point that is normally represented in a high dimensional space and maps it to a lower dimensional representation. You generally lose information in the process, but in high-dimensional spaces there's often a lot of empty space that you can get rid of without losing much. The closest analogy I can think of is compressing a CD to mp3. You are losing information in the process, but if done correctly, the human ear can't tell much of a difference.
Why do this? One obvious reason is so you can plot highly dimensional data in 2D and 3D and get a better sense of certain spatial relationships. Once reduced, the vector components are difficult to describe in plain language. So it's not like "x is time and y is trades."
It's a confusing concept if you've never seen it before but it's very powerful and a common technique used in data science.
[deleted] t1_jbyzuz0 wrote
[deleted]
Viewing a single comment thread. View all comments