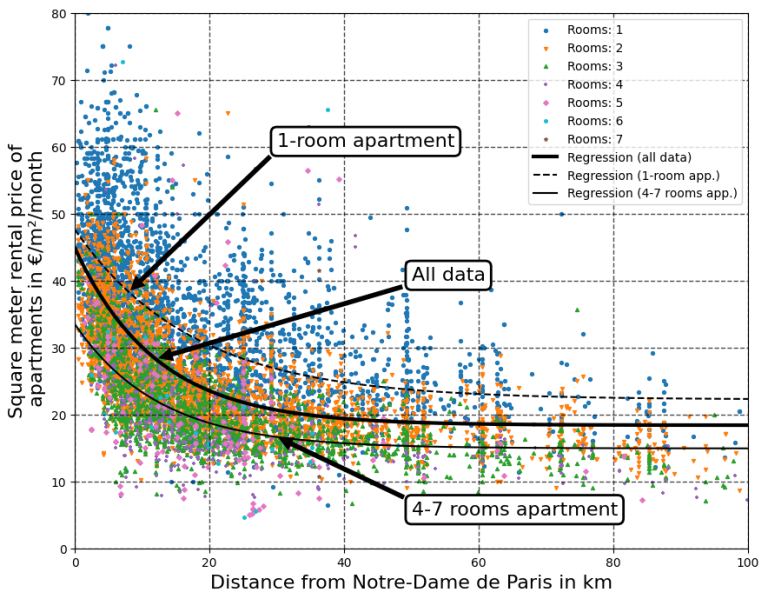
 [OC] Relation between the square meter price of an apartment and distance from Notre Dame de Paris in Paris and Ile-de-France
[OC] Relation between the square meter price of an apartment and distance from Notre Dame de Paris in Paris and Ile-de-Francehmiemad t1_jdqtj4j wrote
In the article, Fig 12, on the left, we see a clearer relation of total rent vs size. There is a clear intercept (337.55€, say C). I think you should rerun the regression with taking this into account : (price-C)/size vs distance. And finally, when you find the relation (exp, linear, quad, whatever, say F ), you run a regression on price = C + F(distance) * size.
Also, there are robust ways to run regression, better than just remove the outliers once and rerun. Huber is your friend, as are statsmodel/sklearn (both built on top of scipy).
sudu1988 OP t1_jdqtuw6 wrote
Thanks for feedback, I'll try this next week.
hmiemad t1_jdtapst wrote
Once you get it, map the standardized error with colorscale. And don't do the cheap average per departement or municipality. I know for a fact that in 18th and 17th arrondissements of Paris, you can get very different rates. So for each appartment, one point on the map with the error as color. Rich neighbourhoods should pop up.
​
edit : for mapping purposes, take a look at geopandas. very close to pandas. easy to use : gdf.plot()
Viewing a single comment thread. View all comments